Overview
Data validation involves systematically checking and cleaning data to prevent incorrect, incomplete, or irrelevant data from entering a database, thereby safeguarding the reliability of subsequent analyses. Numerous forms of data validation exist, and most validation processes involve conducting one or more of these checks to verify the accuracy of the data prior to its storage in a database.
To ensure effective implementation of data validation, organizations should adhere to best practices and techniques. Data validation ensures that the data is accurate, reliable, and consistent, thus enabling better-informed decisions and improved overall performance.
Garbage in, garbage out—consequences: the output is only ever as good as the input.
Data validation yields high-quality outputs. More specifically, its methods work to ensure the accuracy, quality, and integrity of data before its use. Data validation involves systematically checking and cleaning data to prevent incorrect, incomplete, or irrelevant data from entering a database, thereby safeguarding the reliability of subsequent analyses.
This way, organizations—of all kinds and sizes—can know that their operations are backed by reliable data, mitigating the risk of unnecessary, costly errors from garbage in.
Learn more about data validation and its types, best practices, and processes below.
Types of data validation
Numerous forms of data validation exist, and most validation processes involve conducting one or more of these checks to verify the accuracy of the data prior to its storage in a database.
Let’s consider five key types of data validation:
- Data type check. A data type check rule validates that the entered data matches the required data type for a specific field. For instance, if a field only accepts text, any input that is not text—such as numeric or special characters—should be rejected by the system.
- Code check. A code check rule ensures that the input for a field aligns with a specific set of acceptable values or follows established formatting criteria. This is especially applicable in scenarios where entries must conform to standardized formats, such as International Standard Book Numbers (ISBNs) for books or vehicle identification numbers (VINs) for cars.
- Range check. A range check ensures input data adheres to a specified range. For instance, in a temperature control system, the acceptable range may be set between -10°C and 35°C. Any input outside this range—such as -15°C or 40°C—would be considered invalid and rejected by the system.
- Format check. Data type format checks ensure that inputs conform to a predefined structure specific to certain data types. A typical example is ensuring that phone numbers are entered in a consistent format, such as "(XXX) XXX-XXXX" or "XXX-XXX-XXXX."
- Consistency check. A consistency check is a method of verifying that data is logically coherent and correctly entered. For example, it may involve ensuring that a patient's recorded age aligns with their date of birth.
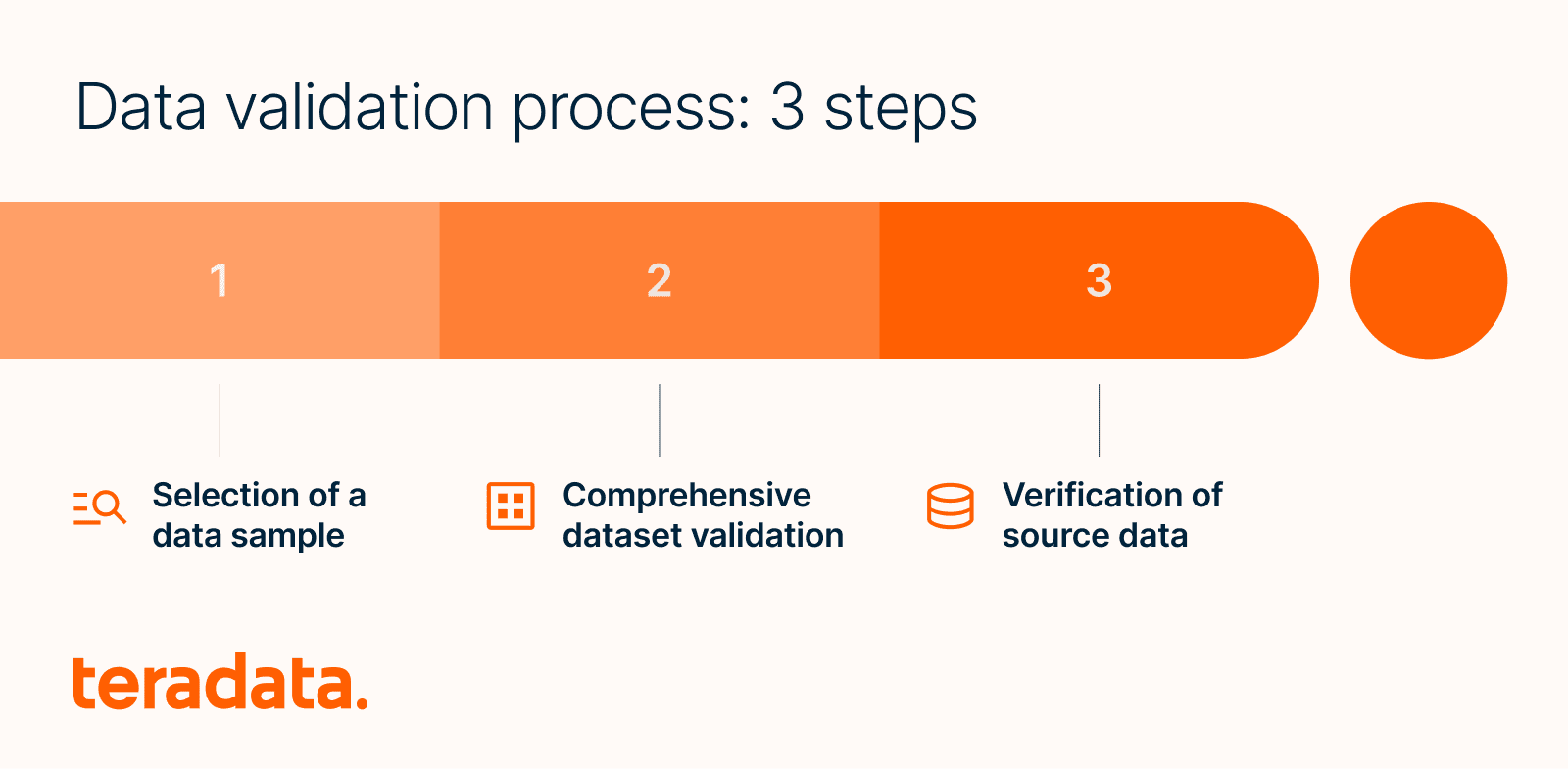
The data validation process: Three steps
Data validation typically involves the following steps:
- Selection of a data sample. Initially, a subset of the data is chosen—particularly in cases where the dataset is extensive. Validating a smaller, representative sample is more feasible than assessing the entire dataset. The size of this sample should be proportional to the overall data volume, and an acceptable error margin should be established at the outset.
- Comprehensive dataset validation. The next phase involves thorough validation to ensure the dataset encompasses all necessary data elements.
- Verification of source data. In the final step, the source data's attributes—including its value, structure, and format—are compared against the schema of the destination. This stage involves checking for any redundant, partial, or inconsistent values.
Data validation tools
These three stages of data validation can be executed using scripting, open-source tools, or enterprise-grade solutions.
Scripting languages, while effective, require a significant investment in terms of human resources, involving the manual creation, execution, and review of scripts. Although this approach allows for a high degree of customization and control, it’s less efficient compared to other methods, largely due to the intensive manual involvement required.
In contrast, enterprise tools provide a more streamlined solution, encompassing both data validation and repair functionalities. These tools, while facilitating enhanced security and reliability, entail a higher financial investment and the necessity for additional infrastructural support.
Open-source tools offer a more budget-friendly alternative. Predominantly cloud-based, these tools balance cost-effectiveness with functional capability and serve as an attractive option for organizations seeking a middle ground between performance and expense. Recognize, however, that these tools require a certain degree of technical proficiency, limiting their accessibility to users without the requisite expertise.
Both open-source and enterprise tools can be split into various categories:
- Data quality tools (Informatica Data Quality)
- Orchestrators (Airflow, Cloud Composer)
- Reporting and business intelligence (BI) tools (Tableau, Apache Superset)
- Data visualization (Power BI, D3.js)
- Cloud storage solutions (Amazon S3)
Best practices and techniques for implementing data validation
To ensure effective implementation of data validation, your organization should adhere to the following three best practices and techniques.
Best practice #1: Cross-source data validation
Structured query language (SQL) data verification methods allow professionals to cross-reference distinct data sources by merging them and identifying discrepancies. This approach is particularly useful for addressing data quality issues arising from various source systems or for contrasting comparable data at diverse points in a business's lifecycle. Yet, this approach’s feasibility largely depends on the data size, as it can become costly, demanding extensive resources.
Best practice #2: Bi-directional data verification
Source system loop-back verification is an effective yet often overlooked method. This technique involves a comprehensive comparison at the aggregate level to ensure the data in question aligns with the original source. The key here is to establish that the information extracted from one system is in complete harmony with what is stored in another, thereby maintaining consistency and avoiding discrepancies.
Best practice #3: Error identification and resolution
Ensuring the integrity and high quality of gathered data involves implementing a systematic approach to monitor and address common errors. This includes identifying variations from expected field sizes, instances of data that fall outside predefined ranges or patterns, incorrect data formats, and repeated instances of duplicate or inconsistent entries, among others. By consolidating these checks, it becomes easier to pinpoint areas more susceptible to data quality issues.
Data validation and ELT/ETL
Data validation is a critical step in data pipelines, especially in exchange, load, and transform (ELT) or exchange, transform, and load (ETL) workflows. It ensures that the data being moved and transformed is accurate, consistent, and reliable. The data validation process in ELT/ETL includes:
- Defining validation rules: Define what "valid" means for each field or dataset, including data types, required fields, value ranges, formats, and more
- Extracting data: Pull data from source systems, such as databases, application programming interfaces (APIs), and files
- Applying validation checks: Run the defined rules against the extracted data using SQL queries, Python scripts, or built-in data validation tools.
- Flagging or handling errors: Log errors for review, quarantine bad records, correct errors automatically, and reject or skip invalid records if necessary.
- Transforming valid data: Once validated, data can be safely normalized, aggregated, or enriched
- Loading into target system: Load the clean, validated, and transformed data into the destination, such as a data warehouse or data lake.
Data validation challenges
Data validation comes with several challenges, including:
- Inconsistent data formats, making it difficult to apply uniform validation rules
- Missing or incomplete data, leading to inaccurate analysis or system erros if not handled properly
- Ambiguous or incorrect data, which can reduce trust in the dataset and skew results
- Real-time validation constraints, which can slow down systems or create poor user experiences
- Evolving validation rules, requiring frequent updates to logic
- Cross-field validation, adding complexity to validation logic
- Multilingual and localization issues, increasing the complexity of validation rules
- Integration with existing systems, requiring robust mapping and transformation logic
- Scalability, which may require distributed systems or parallel processing
Data validation FAQs
Why do organizations need data validation?
Why do organizations need data validation?
Without data validation, data integrity can be compromised, decisions can be made based on inaccuracies, and operational inefficiencies can occur—all of which could lead to financial or reputational damage. Data validation ensures that the data is accurate, reliable, and consistent, enabling better-informed decisions and improved overall performance.
What is a practical example of data validation?
What is a practical example of data validation?
Consider a clinic’s online medical appointment booking system. This system requires patients to enter their date of birth to ensure that they are eligible for certain age-specific medical services or screenings. Suppose, however, that the system lacks proper data validation for the date of birth field. This oversight can lead to patients scheduling inappropriate services as the system fails to verify age-specific eligibility. Moreover, it can result in compliance issues with age-sensitive health regulations, among other possible concerns.
Implementing a data validation check — whether range, format, or logical checks — on birth dates would ensure the system's accuracy and reliability, directly impacting the clinic's operational efficiency and adherence to health standards.
What's the difference between data validation and data verification?
What's the difference between data validation and data verification?
Data validation ensures that data is correct, meaningful, and useful according to specific rules or constraints. Data verification ensures that data accurately reflects the original source or intent.